

I am writing this post after consolidating my today’s deep search on How to configure celery to run as a Daemon?. I found many articles on the internet which are not enough and clear. After going through all the steps finally, I planned to write a blog which will have complete step-by-step procedure to make celery worker run as a Daemon.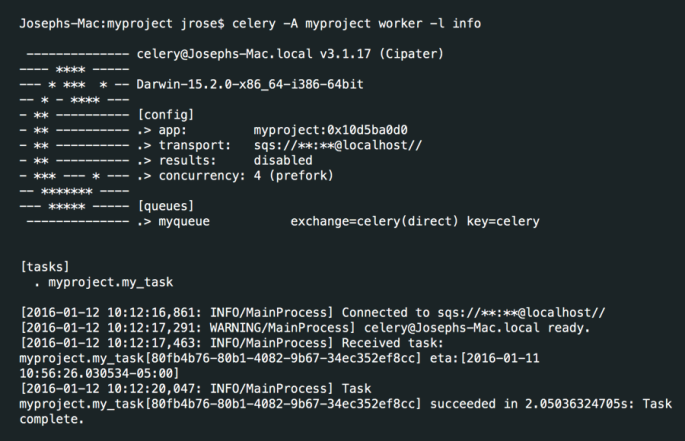 Continue reading “Configure Celery to run as Daemon service”
Continue reading “Configure Celery to run as Daemon service”
Category: Python
Principal Component Analysis in Machine Learning
The definition of Principle Component Analysis(PCA) is Systematized way to transform input features into Principal components. The Principal components are used as new features. PCs are directions in data that maximize variance(obviously minimize information loss) when we Project/Compress down onto them. More variance of data along a PC, higher that PC is ranked. Continue reading “Principal Component Analysis in Machine Learning”
Outliers in Regression
As we saw the Regression is one of the popular machine learning algorithms, I have come over errors and performance of the regression in my previous blog. Outliers are causing in the regression that could also happen like the one in Support Vector Machines or in the Naive Bayes Classifier algorithm do. An outlier is the point of a data that is far away from the regression line. But I had a question that, is it necessary to remove the outliers and do the fit again? The answer is here. Continue reading “Outliers in Regression”
Regression in Machine Learning
I have just started the Lesson 7 in Introduction to Machine Learning Udacity Course, the Regression. Linear Regression is one of the Continuous Supervised Learning methods in machine learning. In other words, it is used to predict the dependent variable(Y) based on values of independent variables(X). It can be used for the cases where we want to predict some continuous quantity like predicting the traffic in a Mall, Dwell time(Time spent in the same position, area, stages of a process). Continue reading “Regression in Machine Learning”
Parameters in Support Vector Machines
Hey! I hope My Blog posts replicates the way I am going through the Machine Learning Course with Udacity. At the middle of Support Vector Machine‘s, I switched over to the next lesson on decision tree. Parameters available are Kernel, C and Gamma. C parameter controls trade-off between Smooth decision boundary and classifying training points correctly. Continue reading “Parameters in Support Vector Machines”
Decision Trees in Machine Learning
Decision trees are the yet another popular algorithm used in Machine Learning for making decisions and it is popular too. It Performs certain recursive actions before it comes at the end result, while plotting the same as visual it looks like a tree, hence called Decision Tree. As much like the Support Vector Machines and Naive Bayes Gaussian Algorithm, decision trees are also helpful in building Classification and Regression models. Continue reading “Decision Trees in Machine Learning”
Kernelized Support Vector Machines
In most of the cases of Supervised Learning Methods, while classification the output will not be linear. Linear Support Vector Machines (SVM’s), worked well for simple kinds of classification problems where the classes linearly separable or close to linearly separable. Continue reading “Kernelized Support Vector Machines”
Support Vector Machines
SVM’s are a set of supervised Learning methods used for, SVM’s are a set of supervised Learning methods used for,
(i) Classification,
(ii) Regression and
(iii) Outliers detection Continue reading “Support Vector Machines”
Special Variables in Python and Inheritance
This special variable is to get the Doc String used in any any class of function. Now Consider this turtle.Turtle.__doc__ will return the Documentation of the Class Turtle. To use the __doc__ in Movie Class we created earlier Continue reading “Special Variables in Python and Inheritance”
Google Style Guide for python
We do have our own Way of Writing Codes. In order to have the standardness in Code, to make our code clean and to follow the Python Code Style which is used widely commonly, it is essential for us to Follow the Google Style Style for Python. Here are some useful guides which I read and consolidated from here. Continue reading “Google Style Guide for python”
